
はじめに
AIにどうやって文章を読ませる?
では、実際にどのような方法で行っているかをお話ししましょう。まずは、モデルを確定するために、アナリストのレポートを選ぶところから始めます。ポジティブ文脈の過去のレポートを数万本、ネガティブな文脈のレポートを数万本程度選びます。
ポジティブやネガティブというのは、さまざまな基準があります。たとえば、株価の上昇に大きなインパクトを与えた過去のレポートをポジティブとするケースなどです。学習データなので、過去のものを使います。
こうしたレポートをAIに読ませるのですが、読ませるといっても、まずは文章を単語に分けていきます。
たとえば、「猛暑で、アイスの売り上げが好調」という文としたら、「猛暑」「で」「アイス」「の」「売り上げ」「が」「好調」と7個に分けます。これを「分かち書き」といいます。そして、助詞を除きます。すると「猛暑」「アイス」「売り上げ」「好調」と4つになります。
比較的シンプルな方法だと、ポジティブなレポートに登場する単語はどのようなものが多いか、逆にネガティブなレポートに登場する単語はどのようなものかを集計します。集計の際には、それぞれの単語に数字の連番を振るので、コンピュータ上では番号で管理します。下表は、ポジティブとネガティブ単語の一例です。

これでいったん評価の仕組みを確定したら、実際のモデルの運営になります。今度は過去のものを使うのでなく、新しくアナリストレポートが出たら、ポジティブとネガティブの単語のどちらが多いかで得点づけを行います。
レポートを“ベクトル”でとらえる
実は、こうした方法は昔から「テキストマイニング」と呼ばれてきました。
コンピュータの性能が今ほどでない時代には、モデルを確定する段階で最初にレポートを読み込ませることをしないで、事前に人間がポジティブ語やネガティブ語はどのようなものがあるのかを決めておきます。そして、運営の段階で人間がレポートに何個のワードがあったかを数えるところだけ、コンピュータに任せるということをしていました。
コンピュータの性能が向上したことにより、ポジティブとネガティブ語もコンピュータが探してくれます。この方法でも業績修正の予兆をとらえるのに一定のバリエーションがありますが、アナリストレポートを評価する方法にはさまざまなものがあります。
近年、注目されている方法の1つが「ドックツーベック(Doc2Vec)」というもの。ドックは英語で「文書(ドキュメント)」の意味で、ベックは「ベクトル表現」という意味です。文書をベクトルに変換するというものですが、行列表記などで説明されるもので、それを聞いても一般の人はわかりにくいものです。
このドックツーベックを使った方法にもいくつかの種類がありますが、平たく言うと、たとえばAIが過去のレポートを学習する際に、先に挙げた「猛暑」「アイス」「売り上げ」「好調」などのレポートに出てくる文を読み込んで単語別に見るのでなく、レポート全体としてそれぞれのレポートの文章の傾向をとらえるものです。
そして、実際の運営では、新しく読み込ませたレポートの文章全部が、学習済みのポジティブ、ネガティブのいずれかに近いか、「類似度」という尺度を使って評価します。ドックツーベックは難しいので、「大量な文章から似ていることを客観的評価する」というAIが得意とすることを最大限に利用した手法として知ってもらえれば十分です。
気がかりなセンチメント指数の動き
実は、こうしたAIによるアナリストレポートの分析は、個別銘柄を選ぶのに使うだけではありません。銘柄別の評価を集計すると、株式市場全体の将来を予測することにも使えます。ポジティブになる企業が全体的に増えれば、将来の業績の上方修正も増えるため、株価も上昇する傾向があるからです。
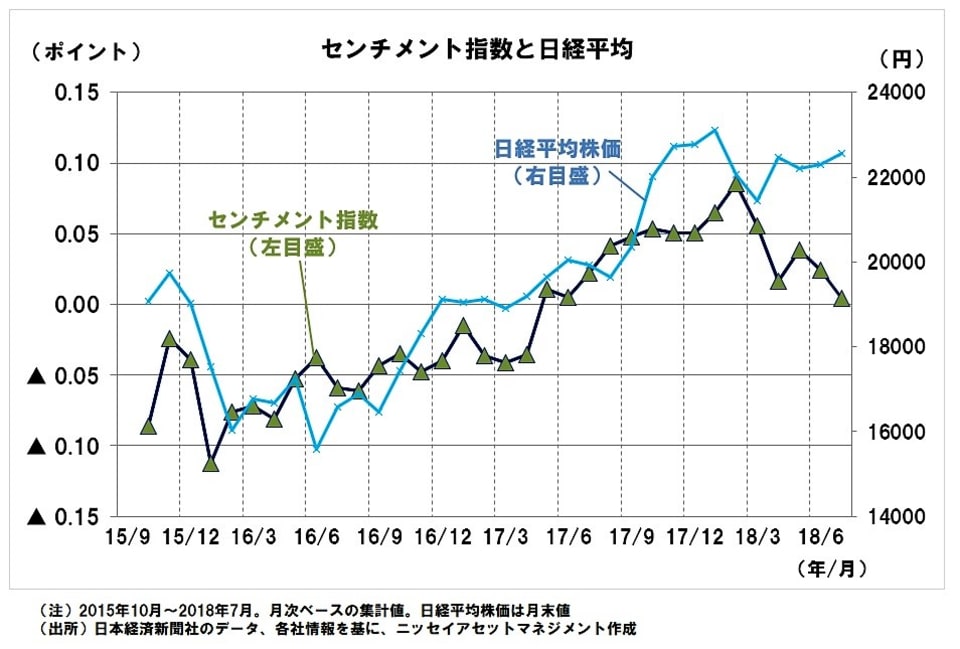
上図では、われわれがアナリストレポートをAIで評価して、それを市場全体で集計しました。私たちは「センチメント指数」と呼んでいます。直近の7月にかけてやや下がっているのが、相場の先行きに気がかりではあります。